Introduction
Imagine you’re baking a cake. You start by gathering ingredients, mix them together, bake it, check if it’s done, and finally, you serve it to guests. In the world of machine learning, the process is quite similar: you collect data (ingredients), train a model (mixing), evaluate its performance (checking if it’s baked), and finally, deploy it (serving the cake).
In this blog, we’ll walk through building an entire machine learning “baking” pipeline using Python, MLFlow, and Poetry. By the end, you’ll not only have your model trained and ready, but also served for others to enjoy through an API!
Objectives
- Ingest Data: Collect and preprocess the raw data (like gathering and chopping ingredients for a recipe).
- Train a Model: Mix the ingredients to create the cake batter (train the model).
- Evaluate the Model: Check if the cake is baked to perfection (evaluate the model’s performance).
- Deploy the Model: Serve the cake to your guests (deploy the model so it can be used for predictions).
Prerequisites
Before we dive in, make sure you have some basic tools ready, like knowing how to code in Python, a basic understanding of machine learning, and familiarity with MLFlow and Poetry. It’s like knowing your way around the kitchen before baking!
Step 1: Setting Up the Pipeline
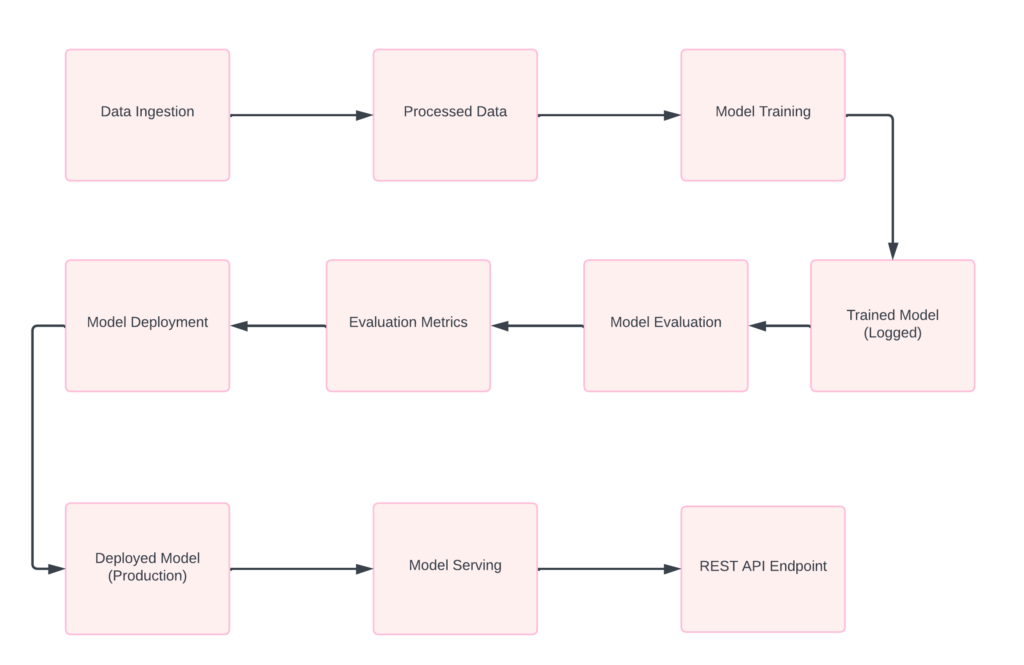
Our machine learning pipeline is like an assembly line in a factory. Each step handles a specific task and passes the output to the next step. In our case, the pipeline has four main stages: Data Ingestion, Model Training, Model Evaluation, and Model Deployment.
Directory Structure
Think of this directory structure as the different workstations in your kitchen, where each station is responsible for a specific part of the cake-making process.
mlflow-pipeline/
├── data-ingestion/
│ ├── MLproject
│ ├── ingest.py
│ └── data/
│ └── dataset.csv
├── model-training/
│ ├── MLproject
│ ├── train.py
│ └── data/
│ └── target.csv
├── model-evaluation/
│ ├── MLproject
│ └── evaluate.py
└── model-deployment/
├── MLproject
└── deploy.pyEach folder (station) handles a different task, from preparing ingredients to serving the final dish.
1.1 Data Ingestion
Analogy: Think of this step as going to the market, buying fresh ingredients, and washing them before use.
In the data-ingestion step, we load the raw dataset (our ingredients), preprocess it (washing and chopping), and save the processed data so it’s ready for the next step.
Ingest Script (ingest.py)
This script is like your sous-chef. It reads the raw data (ingredients), does some basic cleaning (preprocessing), and hands over the prepped data for further use.
MLproject File
The MLproject file is like the recipe card that tells MLFlow how to execute this step. It includes instructions like which script to run and what parameters to use.
name: data-ingestion
entry_points:
main:
command: "poetry run python ingest.py --data_path {data_path}"
parameters:
data_path: {type: str, default: 'data/dataset.csv'}1.2 Model Training
Analogy: Now that our ingredients are prepped, it’s time to mix them and bake the cake.
In the model-training step, we train a linear regression model. This is where the magic happens—the raw data (ingredients) is transformed into a trained model (the cake batter).
Training Script (train.py)
This script trains a simple linear regression model. It’s like your mixer, blending the ingredients together to form a smooth batter. It also registers the model in MLFlow, which is like writing down your recipe so you can bake it again later.
MLproject File
This file tells MLFlow how to handle the training process.
name: model-training
entry_points:
main:
command: "poetry run python train.py"
1.3 Model Evaluation
Analogy: The cake is out of the oven, but we need to taste it to ensure it’s as delicious as expected.
In the model-evaluation step, we evaluate the model’s performance by comparing its predictions with the actual outcomes, just like tasting the cake to ensure it’s perfectly baked.
Evaluation Script (evaluate.py)
This script loads the trained model, makes predictions, and calculates the error (e.g., how far off it was from the true values). This is like checking if the cake has the right texture and flavor.
MLproject File
This file tells MLFlow how to handle the evaluation process.
name: model-evaluation
entry_points:
main:
command: "poetry run python evaluate.py"
1.4 Model Deployment
Analogy: The cake is ready to be served! Let’s present it to the guests.
In the model-deployment step, we transition the trained model to the production stage, making it available for others to use (serve the cake).
Deployment Script (deploy.py)
This script handles the final transition of the model to production, ensuring that it’s ready to be served via an API.
MLproject File
This file provides MLFlow with the instructions to handle the deployment process.
name: model-deployment
entry_points:
main:
command: "poetry run python deploy.py"
Step 2: Orchestrating the Pipeline
Analogy: Our kitchen is ready, ingredients are prepped, the cake is baked and tasted. Now, let’s run through the entire process from start to finish in one go!
The orchestrator script run_pipeline.py acts as the head chef, ensuring that each stage is executed in order, from data ingestion to model deployment.
import mlflow
import os
import subprocess
def run_command(command, cwd):
result = subprocess.run(command, shell=True, cwd=cwd)
if result.returncode != 0:
raise Exception(f"Command failed with return code {result.returncode}")
def run_data_ingestion():
run_command("poetry run mlflow run .", cwd=os.path.abspath("../data-ingestion"))
def run_model_training():
run_command("poetry run mlflow run .", cwd=os.path.abspath("../model-training"))
def run_model_evaluation():
run_command("poetry run mlflow run .", cwd=os.path.abspath("../model-evaluation"))
def run_model_deployment():
run_command("poetry run mlflow run .", cwd=os.path.abspath("../model-deployment"))
if __name__ == "__main__":
run_data_ingestion()
run_model_training()
run_model_evaluation()
run_model_deployment()
Step 3: Serving the Model
Analogy: The cake is on the table, and now it’s time to serve it to your guests!
Once the model is deployed, we can serve it using MLFlow’s built-in serving feature, which exposes the model as a REST API.
mlflow models serve -m "models:/MyModel/Production" -p 1234
This command starts a server where others can send data to get predictions—just like serving slices of cake to your guests.
Conclusion
In this blog, we took a hands-on approach to building and deploying a machine learning pipeline from scratch. Each step of the pipeline was carefully designed to ensure the model’s success, just like following a recipe to bake the perfect cake. By leveraging tools like MLFlow and Poetry, we’ve created a robust, trackable, and scalable solution that can be easily managed and deployed.
Now, your model is not only trained and evaluated but also ready to be served and consumed by real-world applications. This pipeline provides a strong foundation for any machine learning project, ensuring that all steps are reproducible and efficient.
Next Steps
- Experiment with different recipes (models): Just as you might try baking a chocolate cake or a cheesecake, experiment with different machine learning models.
- Expand your kitchen (pipeline): Add more ingredients (data sources), try different cooking techniques (hyperparameter tuning), or monitor your cake once it’s served (model monitoring).
With this pipeline structure, you’re well on your way to becoming a master chef in the kitchen of machine learning. Whether you’re experimenting with new recipes or scaling up for a full-course feast, the possibilities are endless. If you’re looking for a scalable implementation of this pipeline or eager to explore how AI/ML can boost your business, feel free to schedule a Free Consultation with our expert team. Happy modeling, serving, and discovering new flavors of AI/ML!





")